Problems I managed solve in 6 hours for COMP4128 Programming Challenges. Got me 400 points out of 800 (median score was also 400 if I’m reading this scoreboard correctly), so I’m very happy about that.
After doing pretty badly on the weekly problem sets, I honestly thought I would be screwed, but I guess persevering on the problem sets does make me better at this stuff.
Considering this is my first experience with programming challenges, it feels good to know I can also solve problems like these if I try. (But of course, I know these are really easy problems and I still have a long way to go!)
Problem A: Cryptography
Claude is developing a new system to encrypt information. In his system, a key is a tuple of five integers. The encryption is based on three fundamental operations.
Letting ã = (a1, a2, a3, a4, a5) and b̃ = (b1, b2, b3, b4, b5):
• rotate(ã) = (a5, a1, a2, a3, a4),
• multiply(ã, b̃) = (a1*b1, a2*b2, a3*b3, a4*b4, a5*b5),
where each number in the result is taken modulo 1,000,000,007.
• combine(ã, b̃) = multiply(ã, rotate(b̃)).
To encrypt a key, Claude iterates the combine operation n times as follows:
combine(ã, n) = combine(combine(ã, n − 1), ã)
combine(ã, 0) = ã.
Help Claude produce the encrypted key.Constraints
• 1 ≤ n ≤ 1018.
• 0 ≤ a1, a2, a3, a4, a5 < 1,000,000,007.Subtasks
A1 (30 points): 1 ≤ n ≤ 100,000.
A2 (70 points): no restrictions.How I solved this problem
Subtask A1
Simulation using tuples as a warm up problem.
Subtask A2
The problem text is confusing because there are two combine() functions, so change the iteration function to iter().
iter(a, n) = combine(iter(a, n-1), a)
iter(a, 0) = a
iter(a, n) = combine(iter(a, n-1), a)
= combine(combine(iter(a, n-2), a), a)
= combine(combine(combine(iter(a, n-3), a), a), a)Expand and realise the terms are basically ((A1*A5)*A5)..repeated n times.
Use fast exponentiation under modulus.
Solution (Original, C++)
#include <iostream>
#include <algorithm>
#include <vector>
#include <sstream>
#include <cassert>
#include <queue>
#include <set>
#include <map>
#ifdef DEBUG
#include <fmt/format.h>
#include <fmt/ranges.h>
#include <fmt/ostream.h>
#else
namespace fmt { void print(...) {} }
#endif
using namespace std;
uint64_t pow(uint64_t x, uint64_t n, uint64_t m) {
if (n == 0) return 1;
uint64_t a = pow(x, n/2, m);
a = a * a % m;
if (n%2 == 1) a = a * x % m;
return a;
}
using enctup = tuple<uint64_t, uint64_t, uint64_t, uint64_t, uint64_t>;
const uint64_t M = 1000000007llu;
enctup encryptfast(enctup const& tup, uint64_t n) {
return enctup(
(get<0>(tup) * pow(get<4>(tup), n, M)) % M,
(get<1>(tup) * pow(get<0>(tup), n, M)) % M,
(get<2>(tup) * pow(get<1>(tup), n, M)) % M,
(get<3>(tup) * pow(get<2>(tup), n, M)) % M,
(get<4>(tup) * pow(get<3>(tup), n, M)) % M
);
}
ostream& operator<<(ostream& os, enctup const& tup) {
return os << get<0>(tup) << ' '
<< get<1>(tup) << ' '
<< get<2>(tup) << ' '
<< get<3>(tup) << ' '
<< get<4>(tup);
}
int main(void)
{
uint64_t n, a1, a2, a3, a4, a5;
cin >> n >> a1 >> a2 >> a3 >> a4 >> a5;
enctup origtup = enctup(a1, a2, a3, a4, a5);
enctup anstup = encryptfast(origtup, n);
cout << anstup << endl;
return 0;
}
Problem B: Wires
Gilles is trying to wire a circuit board. There are four sides, each with n connection points labelled between 1 and 2n. Each of these labels occurs exactly twice.
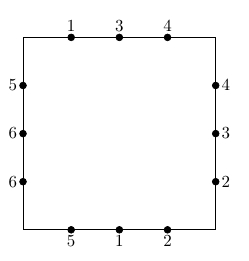 For each pair of connection points with the same label, Gilles wants to place a wire to connect them. These wires may be curved, but they cannot go off the board and they cannot overlap or cross each other.
For each pair of connection points with the same label, Gilles wants to place a wire to connect them. These wires may be curved, but they cannot go off the board and they cannot overlap or cross each other.
 Is it possible for Gilles to place all 2n wires as desired?
Is it possible for Gilles to place all 2n wires as desired?Constraints
• 1 ≤ n ≤ 100,000.
• For all 1 ≤ i ≤ 4 and 1 ≤ j ≤ n, 1 ≤ ai,j ≤ 2n.
• Each value ai,j appears exactly twice.Subtasks
B1 (30 points): 1 ≤ n ≤ 1000.
B2 (70 points): no restrictions.How I solved this problem
At first, I started thinking with a breadth-first search approach – for every connection point, I can use breadth-first search to find the nearest connection point, with a bound that increases. For example, I would first try all connection points that can connect within 1 search, and then I would connect all those with 2 searches, and so on.
Then I realised that’s basically a greedy approach on the distance of connections and I was assuming that it would produce an optimal solution, which turned out to be right.
Now that we have an algorithm for wiring the board, all we have to figure out is whether any such wiring would be valid.
Subtask B1
Sort connection points by the distance to their counterpart. Greedy on the distance, lowest first. I can loop through all connection points in O(n) time and connect them if there are no issues.
For the decision problem of valid wiring, consider the input array of connection points arranged in clockwise order. For any connection point you consider, there is a counterpart, and between those two points, there is an “inside” and “outside” as shown on the diagram below.
. x . . x . . . x . . x connected?
1 3 4 6 3 2 2 1 5 4 6 5
|--- inside --|
|--| |--| outsideLoop through the “inside”. If any are connected, consider whether it is connected to the “outside” and if so, then we cannot connect the two points under consideration (the two points that define the “inside”) as it would cross a prior greedy optimal solution.
Subtask B2
The above linear sweep approach is not good enough, because our worst-case scenario is a linear sweep for every connection point, which will be 10B steps.
But we can simplify the problem. In terms of array indices, we can store the index to its counterpart if it is connected, or the index to itself otherwise.
. x . . x . . . x . . x connected?
0 1 2 3 4 5 6 7 8 9 a b array index
0 4 2 3 1 5 6 7 b 9 a 8 counterpart index
1 3 4 6 3 2 2 1 5 4 6 5
|--- inside --|
|--| |--| outsideUse two separate range trees to query the minimum and maximum value of the inside range. Check if either the mininum or maximum lies in the outside range. We have checked whether a conflict exists in O(log n) time.
Tricks: For some reason the range tree implementation I copied from the lecture slides overran its buffer into the one and two array, so I just increased its size massively and it passed… so yeah, I must have screwed up one of the calculations…?
Solution (Original, C++)
#include <iostream>
#include <algorithm>
#include <vector>
#include <sstream>
#include <cassert>
#include <queue>
#include <set>
#include <map>
#include <cmath>
#include <iomanip>
#ifdef DEBUG
#include <fmt/format.h>
#include <fmt/ranges.h>
#include <fmt/ostream.h>
#else
namespace fmt { void print(...) {} }
#endif
using namespace std;
const int MAXN = 100000;
int n;
vector<int> clockwise;
// For given number as index, stores the index in the
// clockwise array, first occurring stored in one, and then two
int one[2*MAXN];
int two[2*MAXN];
// for a given number, returns the distance
// to the counterpart, accounting for counter-clockwise wraparound
int distance(int x) {
assert(n > 0);
int cw = two[x] - one[x];
assert(cw > 0);
int ccw = one[x] + ((4*n) - two[x]);
// fmt::print("ccw={} x={} n={} one={} two={}\n", ccw, x, n, one[x], two[x]);
assert(ccw > 0);
return min(cw, ccw);
}
/* BEGIN RANGE TREE IMPLEMENTATIONS */
/* MAX RANGE TREE */
// the number of additional nodes created can be as high as the next power of two up from MAX_N (131,072)
int max_tree[(4*MAXN) + 524288 + 1000000];
// a is the index in the array. 0- or 1-based doesn't matter here, as long as it is nonnegative and less than MAX_N.
// v is the value the a-th element will be updated to.
// i is the index in the tree, rooted at 1 so children are 2i and 2i+1.
// instead of storing each node's range of responsibility, we calculate it on the way down.
// the root node is responsible for [0, MAX_N)
void max_update(int a, int v, int i = 1, int start = 0, int end = 4*MAXN) {
// this node's range of responsibility is 1, so it is a leaf
if (end - start == 1) {
max_tree[i] = v;
return;
}
// figure out which child is responsible for the index (a) being updated
int mid = (start + end) / 2;
if (a < mid) max_update(a, v, i * 2, start, mid);
else max_update(a, v, i * 2 + 1, mid, end);
// once we have updated the correct child, recalculate our stored value.
max_tree[i] = max(max_tree[i*2], max_tree[i*2+1]);
}
/*
* range tree query
*/
// query the sum in [a, b)
int max_query(int a, int b, int i = 1, int start = 0, int end = 4*MAXN) {
// the query range exactly matches this node's range of responsibility
if (start == a && end == b) return max_tree[i];
// we might need to query one or both of the children
int mid = (start + end) / 2;
int av = 0;
int bv = 0;
// the left child can query [a, mid)
if (a < mid) av = max_query(a, min(b, mid), i * 2, start, mid);
// the right child can query [mid, b)
if (b > mid) bv = max_query(max(a, mid), b, i * 2 + 1, mid, end);
return max(av, bv);
}
/* MIN RANGE TREE */
// the number of additional nodes created can be as high as the next power of two up from MAX_N (131,072)
int min_tree[(4*MAXN) + 524288 + 1000000];
// a is the index in the array. 0- or 1-based doesn't matter here, as long as it is nonnegative and less than MAX_N.
// v is the value the a-th element will be updated to.
// i is the index in the tree, rooted at 1 so children are 2i and 2i+1.
// instead of storing each node's range of responsibility, we calculate it on the way down.
// the root node is responsible for [0, MAX_N)
void min_update(int a, int v, int i = 1, int start = 0, int end = 4*MAXN) {
// this node's range of responsibility is 1, so it is a leaf
if (end - start == 1) {
min_tree[i] = v;
return;
}
// figure out which child is responsible for the index (a) being updated
int mid = (start + end) / 2;
if (a < mid) min_update(a, v, i * 2, start, mid);
else min_update(a, v, i * 2 + 1, mid, end);
// once we have updated the correct child, recalculate our stored value.
min_tree[i] = min(min_tree[i*2], min_tree[i*2+1]);
}
/*
* range tree query
*/
// query the sum in [a, b)
int min_query(int a, int b, int i = 1, int start = 0, int end = 4*MAXN) {
// the query range exactly matches this node's range of responsibility
if (start == a && end == b) return min_tree[i];
// we might need to query one or both of the children
int mid = (start + end) / 2;
int av = 1e9;
int bv = 1e9;
// the left child can query [a, mid)
if (a < mid) av = min_query(a, min(b, mid), i * 2, start, mid);
// the right child can query [mid, b)
if (b > mid) bv = min_query(max(a, mid), b, i * 2 + 1, mid, end);
return min(av, bv);
}
void test(void) {
fmt::print("Testing...\n");
max_update(0, 1);
max_update(2, 10);
assert(max_query(0, 3) == 10);
assert(max_query(0, 5) == 10);
assert(max_query(0, 2) == 1);
assert(max_query(10, 50) == 0);
fmt::print("Test success!\n");
abort();
}
/* END RANGE TREE IMPLEMENTATIONS */
int32_t main(void)
{
cout << fixed << setprecision(10);
fill(one, one+(2*MAXN), -1);
fill(two, two+(2*MAXN), -1);
cin >> n;
for (int i = 0; i < (4*n); ++i) {
max_update(i, i);
min_update(i, i);
}
for (int i = 0; i < (4*n); ++i) {
int v;
cin >> v;
v -= 1;
clockwise.push_back(v);
if (one[v] == -1) {
assert(two[v] == -1);
one[v] = i;
} else {
assert(two[v] == -1);
two[v] = i;
}
}
vector<pair<int, int>> dpts; // (distance to counterpart, number)
for (int i = 0; i < (2*n); ++i) {
dpts.push_back(pair<int, int>(distance(i), i));
fmt::print("distance for {}={}\n", i+1, distance(i));
}
sort(dpts.begin(), dpts.end());
for (auto const& p : dpts) {
int num = p.second;
if (max_query(one[num]+1, two[num]) > two[num]) {
cout << "NO" << endl;
return 0;
}
if (min_query(one[num]+1, two[num]) < one[num]) {
cout << "NO" << endl;
return 0;
}
max_update(one[num], two[num]);
min_update(one[num], two[num]);
max_update(two[num], one[num]);
min_update(two[num], one[num]);
}
cout << "YES" << endl;
return 0;
}
Problem C: Assemble
Catherine is building a spaceship from a variety of parts. All the parts have been built in various cities, connected by a rail network. The last step is to transport all the spaceship parts to a single city for assembly.
There are n cities in the network, with m railroads each joining a pair of cities. It is possible to travel between any pair of cities by some sequence of railroads. Each railroad has an associated integer denoting its level. Buying a freight pass at level k allows the owner to send unlimited amounts of freight along any railroad of level at most k.
Freight passes are very expensive, so help Catherine find the lowest level of freight pass required to gather all spaceship parts in a single city.Constraints
• 1 ≤ n ≤ 100,000.
• n − 1 ≤ m ≤ 100,000.
• 1 ≤ p ≤ 100,000.
• For all 1 ≤ i ≤ m, 1 ≤ ai < bi ≤ n and 1 ≤ li ≤ 100,000.
• For all 1 ≤ i ≤ p, 1 ≤ ci ≤ n.Subtasks
C1 (50 points): 1 ≤ n ≤ 1,000, n − 1 ≤ m ≤ 1,000.
C2 (50 points): no restrictions.How I solved this problem
Subtask C1
First, clearly a binary search and decision problem on the value of k.
Because the graph is undirected, if I can reach a city from the destination, then I can also reach the destination from that city as well.
That means if I run BFS or DFS, then I can check reachability in O(|V| + |E|) time which is about 200_000.
But the city where I must assemble things is not defined and there are up to 100_000 cities.
Binary search is log2(100_000) = around 17.
For full problem 340B steps vs for subtask 34M steps, so linear sweep of all cities will work for subtask but not for the full problem.
Subtask C2
Let’s be smarter. For each level that is undergoing binary search, I should be able to run something that is not BFS or DFS to find out what cities are reachable from a given city for all cities.
Perhaps I can use a disjoint-set union? If I loop through all the edges, and even if I scan through all cities once afterwards, that’s still only 200_000. A union-find data structure with path compression and subtree balancing runs in O(log(n)). 17*17*200_000 is well within the bounds.
For each binary search decision, only consider edges that can be used with a level k pass.
Solution (Original, C++)
#include <iostream>
#include <algorithm>
#include <vector>
#include <sstream>
#include <cassert>
#include <queue>
#include <set>
#include <map>
#ifdef DEBUG
#include <fmt/format.h>
#include <fmt/ranges.h>
#include <fmt/ostream.h>
#else
namespace fmt { void print(...) {} }
#endif
using namespace std;
class union_find
{
public:
union_find(size_t size) : parent_(size), subtree_size_(size) {
for (size_t i = 0; i < size; ++i) {
parent_[i] = i; subtree_size_[i] = 1;
}
}
auto root(int x) -> int {
// only roots are their own parents
// otherwise apply path compression
return parent_[x] == x ? x : parent_[x] = root(parent_[x]);
}
auto join(int x, int y) -> void {
// size heuristic
// hang smaller subtree under root of larger subtree
x = root(x); y = root(y);
if (x == y) return;
if (subtree_size_[x] < subtree_size_[y]) {
parent_[x] = y;
subtree_size_[y] += subtree_size_[x];
} else {
parent_[y] = x;
subtree_size_[x] += subtree_size_[y];
}
}
private:
vector<int> parent_;
vector<int> subtree_size_;
};
int n, m, p;
using edge = tuple<int, int, int>;
vector<edge> edges; // city1, city2, level
vector<int> parts; // refers to city
bool decision(int k) {
auto uf = union_find(n+1);
for (auto const& e : edges) {
auto c1 = get<0>(e);
auto c2 = get<1>(e);
auto l = get<2>(e);
if (l > k) continue;
uf.join(c1, c2);
}
int mustbe = -1;
for (auto const& c : parts) {
if (mustbe == -1) {
mustbe = uf.root(c);
} else if (uf.root(c) != mustbe) {
return false;
} else {
continue;
}
}
return true;
}
int binarysearch(void) {
int l = -1; // invariant: f(l) = false
int r = 100001; // invariant: f(r) = true
while (l < r-1) {
int m = (l+r)/2;
if (decision(m)) r = m;
else l = m;
}
return r;
}
int main(void)
{
cin >> n >> m >> p;
for (int i = 0; i < m; ++i) {
int a, b, l;
cin >> a >> b >> l;
edges.push_back(edge(a, b, l));
}
for (int i = 0; i < p; ++i) {
int c;
cin >> c;
parts.push_back(c);
}
cout << binarysearch() << endl;
return 0;
}
Problem D: Interception
Yasmin is the administrator for a network of n computers. There are m connections in the network, each joining a different pair of distinct computers ai and bi and allowing messages to be sent in both directions. However, a message may be intercepted by nefarious hackers, with probability pi.
Yasmin knows that if not for these hackers, a message could be sent from any computer to any other, at least indirectly. Help her figure out the probability that such a message is not intercepted, assuming the optimal route is taken.Constraints
• 1 ≤ n ≤ 200.
• n − 1 ≤ m ≤ n(n − 1)/2.
• For all 1 ≤ i ≤ m, 1 ≤ ai , bi ≤ n, ai != bi and 0 < pi < 1.Subtasks
D1 (30 points): for all 1 ≤ i ≤ m, pi = 0.1.
D2 (70 points): no restrictions.How I solved this problem
The first thing to note, if you didn’t read the output section carefully just like me, is to realise that there is no starting node. We have to find the probability of no interception across all pairs of nodes.
Subtask D1
The probability of interception is a simple function of the shortest path. We can find the all-pairs shortest paths using Floyd-Warshall in O(V3) which will run in time. Precompute a table of probabilities with respect to a given distance.
Subtask D2
Note that Floyd-Warshall is a relaxation algorithm, which means we can pretty easily modify how it builds up the all-pairs shortest paths.
Instead of adding weights at the point of relaxation, multiply the weights instead.
Calculate the graph with inverse probabilities to minimise floating-point error (i.e. instead of 0.01 * 0.01, do 0.99 * 0.99, find the max path).
Tricks: __float128, cout << fixed << setprecision(10).
Solution (Original, C++)
#include <iostream>
#include <algorithm>
#include <vector>
#include <sstream>
#include <cassert>
#include <queue>
#include <set>
#include <map>
#include <cmath>
#include <iomanip>
#ifdef DEBUG
#include <fmt/format.h>
#include <fmt/ranges.h>
#include <fmt/ostream.h>
#else
namespace fmt { void print(...) {} }
#endif
using namespace std;
const int MAXN = 200;
__float128 dist[MAXN][MAXN]; // probability of NO INTERCEPTION
using edge = tuple<int, int, __float128>; // undirected edge, probability of NO INTERCEPTION
vector<edge> edges;
int n, m;
void floydwarshall(void) {
// initially, the probability of no interception is 0 (no route)
for (int u = 0; u < n; ++u) for (int v = 0; v < n; ++v) {
dist[u][v] = 0.0;
}
// update the probabilities for every directed edge
for (auto const& e : edges) {
int u = get<0>(e), v = get<1>(e);
__float128 p = get<2>(e);
dist[u][v] = p;
dist[v][u] = p;
}
// every vertex can reach itself
for (int u = 0; u < n; ++u) dist[u][u] = 1.0;
for (int i = 0; i < n; i++) {
for (int u = 0; u < n; u++) {
for (int v = 0; v < n; v++) {
dist[u][v] = max(dist[u][v], dist[u][i] * dist[i][v]);
}
}
}
}
int main(void)
{
cout << fixed << setprecision(10);
cin >> n >> m;
for (int i = 0; i < m; ++i) {
int a, b;
long double p;
cin >> a >> b >> p;
a -= 1; b -= 1;
edges.push_back(edge(a, b, (__float128) 1.0 - p));
}
floydwarshall();
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
cout << (long double) dist[i][j] << ' ';
}
cout << endl;
}
return 0;
}
